SpringData是原先工作用到了的东西,提供一个一致性的,基于spring的项目,用来访问数据(访问数据库),现在来半预习半复习一下
特点 可以访问关系型数据库,也可以访问非关系型数据库
目的 ** 减少数据访问层的开发量**
springData 包含的子项目
Spring Data JPA
Spring Data MongoDB
Spring Data Redis
Spring Data Solr (一个全文搜索的东西)
等等…..
1.传统方式访问数据库 ** jdbc**
get connection
get statement
resultSet
a)添加依赖 1 2 3 4 5 6 7 8 9 10 11 12 13 <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.38</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.10</version> </dependency>
b)开发JDBCUtil 工具类 获取connection
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 /** * 获取connection * @return */ public static Connection getConnection() throws Exception { //获取配置文件的方法,db.properties 是设置好的配置文件 InputStream input = JDBCUtil.class.getClassLoader().getResourceAsStream("db.properties"); Properties properties = new Properties(); properties.load(input); String url = properties.get("jdbc.url").toString(); String username = properties.get("jdbc.username").toString(); String driverClass = properties.get("user.driverClass").toString(); Class.forName(driverClass); Connection conn= DriverManager.getConnection(url, username, ""); return conn; }
db.properties,灰色的就是没有使用过的
1 2 3 4 5 user.driverClass = com.mysql.jdbc.Driver user.username= root user.url=jdbc:mysql:///localhost user.password =
** 使用 springData jdbc 模板访问数据库**
c) DAO 层开发 真的是好复古好复古的写法,DaoImpl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 /** * 传说中的经典写法???? * @return */ public List<Student> selectAllStudents() { Connection conn = null; PreparedStatement preparedStatement =null; ResultSet resultSet=null; List<Student> li = new ArrayList<Student>(); String sql = "select id ,name,age from tb_student "; Student student = null; try { conn = JDBCUtil.getConnection(); preparedStatement = conn.prepareStatement(sql); resultSet = preparedStatement.executeQuery(); while(resultSet.next()){ //获取结果集中int类型的id对应的value int id = resultSet.getInt("id"); String name = resultSet.getString("name"); int age = resultSet.getInt("age"); student = new Student(); student.setAge(age); student.setId(id); student.setName(name); li.add(student); } } catch (Exception e) { e.printStackTrace(); }finally { JDBCUtil.release(resultSet,preparedStatement,conn); } return li; }
2.Spring模板方式访问数据库—-SpringTemplet 配置xml
1 2 3 4 5 6 7 8 <!-- dbcTermplet--> <bean id="jdbcTemplet" class="org.springframework.jdbc.core.JdbcTemplate"> <property name="dataSource" ref="dataSource"/> </bean> <bean id="studentDao" class="com.drazen.dao.impl.SpringJdbcDaoImpl"> <property name="jdbcTemplate" ref="jdbcTemplet"/> </bean>
然后再dao层调用jdbcTemplet:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 private JdbcTemplate jdbcTemplate; public JdbcTemplate getJdbcTemplate() { return jdbcTemplate; } public void setJdbcTemplate(JdbcTemplate jdbcTemplate) { this.jdbcTemplate = jdbcTemplate; } public List<Student> selectAllStudents() { final List<Student> li = new ArrayList<Student>(); String sql = "select id ,name,age from tb_student "; jdbcTemplate.query(sql, new RowCallbackHandler() { public void processRow(ResultSet resultSet) throws SQLException { int id = resultSet.getInt("id"); String name = resultSet.getString("name"); int age = resultSet.getInt("age"); Student student = new Student(); student.setAge(age); student.setId(id); student.setName(name); li.add(student); } }); return li; }
其实这些方式代码量很多,且很重复,人力成本比较高
SpringData 方式 1.开发环境: maven 依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <!-- https://mvnrepository.com/artifact/org.springframework.data/spring-data-jpa --> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-jpa</artifactId> <version>1.10.5.RELEASE</version> </dependency> <!-- https://mvnrepository.com/artifact/org.hibernate/hibernate-entitymanager --> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-entitymanager</artifactId> <version>5.1.0.Final</version> </dependency>
依赖下载完成后,就要配置bean.xml文件
在bean.xml中配置EntityManagerFactory
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"> <property name="dataSource" ref="dataSource"/> <property name="jpaVendorAdapter"> <bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"/> </property> <property name="packagesToScan" value="com.drazen"/> <property name="jpaProperties"> <props> <prop key="hibernate.ejb.naming_strategy">org.hibernate.cfg.ImprovedNamingStrategy</prop> <prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</prop><!--hibernate方言--> <prop key="hibernate.show_sql">true</prop><!--显示sql--> <prop key="hibernate.format_sql">true</prop><!--格式化sql--> <prop key="hibernate.hbm2ddl.auto">update</prop><!--如果没有对应表的话根据实体类生成表--> </props> </property> </bean>
然后,定义Dao层类型的接口,注意,要实现SpringData功能,首先应该extendsorg.springframework.data.repository.Repository@RepositoryDefinition(domainClass = Employee.class, idClass = Integer.class)注解。
Repository类的定义: 1 2 3 4 public interface Repository<T, ID extends Serializable> { }
1)Repository是一个空接口,标记接口Serializable接口
2)如果我们定义的接口EmployeeRepository extends Repository
如果我们自己的接口没有extends Repository,运行时会报错:
添加注解能到达到不用extends Repository的功能
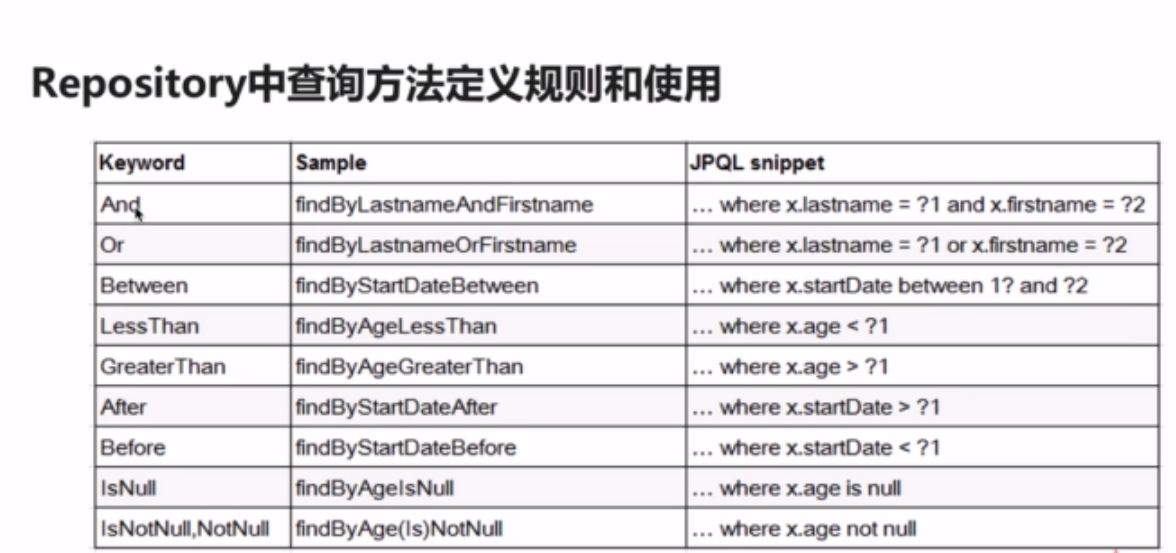
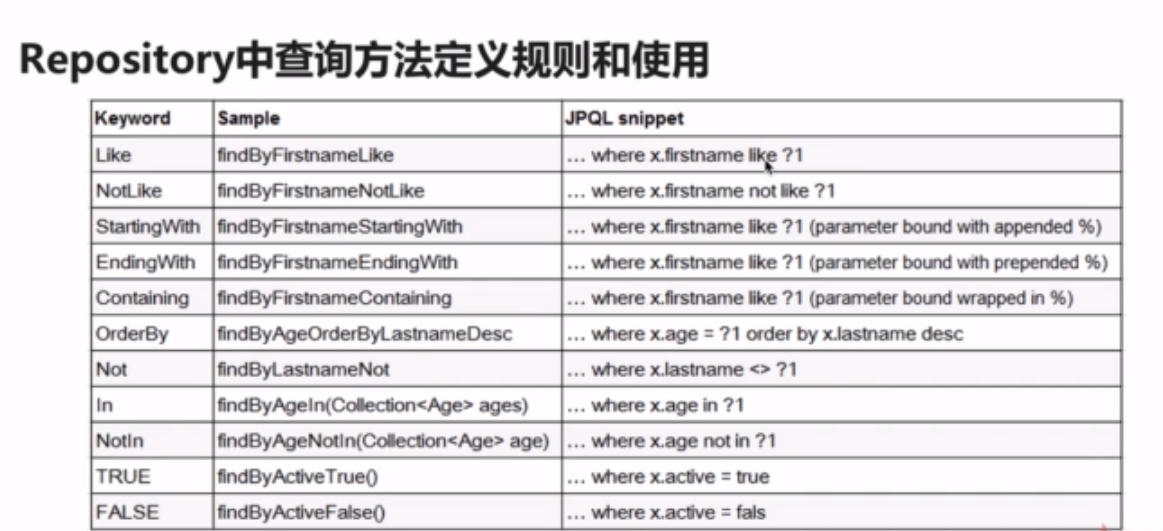
SpringData可以实现通过方法命名规范来自动生成sql进行查询,也就是说,没有方法体
下面是方法名称的命名规范。
要注意: 对于按照方法命名规则来使用的话,有弊端:
方法名会比较长: 约定大于配置
对于一些复杂的查询,是很难实现
@Query是一个更好的使用定制sql的工具注解,我通常把它理解为Mybatis中的类似@Select()酱紫的,而且, 它支持命名参数以及索引参数的使用:?这种参数参数插入
** 支持本地查询**
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Query("select o from Employee o where id=(select max(id) from Employee t1)") public Employee getEmployeeByMaxId(); @Query("select o from Employee o where o.name=?1 and o.age=?2") public List<Employee> queryParams1(String name, Integer age); @Query("select o from Employee o where o.name=:name and o.age=:age") public List<Employee> queryParams2(@Param("name") String name, @Param("age") Integer age); @Query("select o from Employee o where o.name like %?1%") public List<Employee> queryLike1(String name); @Query("select o from Employee o where o.name like %:name%") public List<Employee> queryLike2(@Param("name") String name); @Query(nativeQuery = true, value = "select count(1) from employee") public long getCount(); @Modifying @Query("update Employee o set o.age = :age where o.id = :id") public void update(@Param("id") Integer id, @Param("age") Integer age);
关于SPringData中事物 在写操作中需要事物的支持
@Modifying–允许修改
事物在SpringData中的使用
事务在Spring data中的使用:
使用: 在service层中新建service类,并调用update方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package com.drazen.service; import com.drazen.repository.EmployeeRepository; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import javax.transaction.Transactional; @Service public class EmployeeService { @Autowired private EmployeeRepository employeeRepository; // 手工加入事物注解,并在spring开启自动扫描 @Transactional public void update(Integer id, Integer age) { employeeRepository.update(id, age); } }
关于SpringData JPA 1) CrudRepository接口
这个接口其实就是针对实体进行的机械化写操作,简单粗暴快方法有这些:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 //保存一个实体 <S extends T> S save(S var1); //保存多个实体 <S extends T> Iterable<S> save(Iterable<S> var1); //查找一个实体 T findOne(ID var1); //查看某个实体记录是否存在 boolean exists(ID var1); //查询所有 Iterable<T> findAll(); //根据id组查询所有结果 Iterable<T> findAll(Iterable<ID> var1); //数据字段数量 long count(); //删除单个 void delete(ID var1); //根据实体删除单个 void delete(T var1); //删除一组 void delete(Iterable<? extends T> var1); //删除所有 void deleteAll();
2)PagingAndSortingRepository 接口 支持分页,排序
创建继承了PagingAndSortingRepository的interface 1 2 3 public interface PageRep extends PagingAndSortingRepository<Employee,Integer> { }
1 2 3 4 // 返回所有实体 Iterable<T> findAll(Sort var1); //返回page对象 Page<T> findAll(Pageable var1);
使用PAGE 构建分页1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Autowired private PageRep pageRep; public void getPage(){ //import org.springframework.data.domain.PageRequest; Pageable pageable = new PageRequest(0,5); Page<Employee> page = pageRep.findAll(pageable); //总页数 System.out.println(page.getTotalPages()); // 总记录数 System.out.println(page.getTotalElements()); // 当前第几页 System.out.println(page.getNumber()); // 当前页面的集合 System.out.println(page.getContent()); // 当前页面的记录数 System.out.println(page.getNumberOfElements()); }
PageRep 是一个继承了PagingAndSortingRepository的初始interface
Pageable 是来自org.springframework.data.domain.PageRequest的类
其实page.getContent()获取到的是List
排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public void getSort(){ // import org.springframework.data.domain.Sort.Order; // 进构造器的参数是升序或者降序,类似于order by id desc Sort.Order order = new Sort.Order(Sort.Direction.DESC,"id"); // import org.springframework.data.domain.Sort; Sort sort = new Sort(order); // 将构建好的sort传入PageRequest Pageable pageable = new PageRequest(0,5,sort); Page<Employee> page = pageRep.findAll(pageable); //总页数 System.out.println(page.getTotalPages()); // 总记录数 System.out.println(page.getTotalElements()); // 当前第几页 System.out.println(page.getNumber()); // 当前页面的集合 System.out.println(page.getContent()); // 当前页面的记录数 System.out.println(page.getNumberOfElements()); }
3) JpaSpecificationExecutor 接口
其实我觉得这个方法可能还不如直接写sql,但是好像可以对原生sql有很好的支持
Specification封装了JPA Critical 的查询条件
org.springframework.data.jpa.repository目录下
新建接口继承JpaSpecificationExecutor:
1 2 3 public interface JpaSpecificationRepo extends JpaSpecificationExecutor<Employee> { }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public void testNewInterface(){ // 假如查询条件设定为age>50 Sort.Order order = new Sort.Order(Sort.Direction.DESC,"id"); Sort sort = new Sort(order); // import org.springframework.data.jpa.domain.Specification; Specification<Employee> specification = new Specification<Employee>() { @Override public Predicate toPredicate(Root<Employee> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) { Path path = root.get("age"); /*criteriaBuilder: 构建 * root:实体 * criteriaQuery:查询条件 * * */ return criteriaBuilder.gt(path,50); } }; Pageable pageable = new PageRequest(0,5,sort); Page<Employee> page = pageRep.findAll(specification,pageable); }
总结
总的来说,springdata是一个可以提高开发效率的spring的工具集